Versioning Machine 5.0
- Overview
- Installation & Requisites
- The VM Interface
- Encoding: The Basics
- Encoding: Using Critical Apparatus Tagset
- Line Numbering
- Witness Detail
- Technical Information
Overview
The Versioning Machine (VM) is a software tool designed by literary scholars, programmers, and web designers at several institutions, including An Foras Feasa at the Maynooth University Institute for the Humanities, the Digital Humanities Observatory (DHO), the Maryland Institute for Technology in the Humanities (MITH), and the Office of Digital Collections and Research (DCR) at University of Maryland Libraries. The VM not only provides for elements traditionally found in codex-based critical editions, such as annotation and introductory material, but it also takes advantage of opportunities of electronic publishing. Features include providing a frame to compare diplomatic versions of witnesses side by side, allowing for images of the witness to be viewed alongside the diplomatic edition, inclusion of audio versions of a text, and providing users with an enhanced typology of notes.
The Versioning Machine 1.0 was launched at the 2002 ALLC/ACH (Association for Literary and Linguistic Computing/Association for Computers and the Humanities) Conference in Tubingen, Germany, July 2002. Version 4.0 was released June 2010, with Version 5.0 following in 2015.
The VM supports display of XML texts encoded according to the P5 Guidelines of the Text Encoding Initiative (TEI). To display texts in the VM, you must use the TEI’s “critical apparatus tagset” (TEI.textcrit, see TEI documentation) to encode all witnesses one XML file. Because the critical apparatus tagset offers the most efficient and thorough methodology for inscribing variants in a structured, machine-readable format, choosing this method can be more complicated in terms of markup but rewards the editor in efficiency in encoding. Because using the critical apparatus tagset is at first challenging, instructions to augment the TEI Guidelines are provided below.
Installation & Requisites
To install VM 5.0 locally, fill out the registration form on the VM website to download the zip file that contains a directory that can be installed on any hard drive. Once downloaded, use an unzipping program like WinZip to extract all files in the archive. The contents should unzip into a folder entitled v-machine. To view a description of the product, documentation, and samples, open the file v-machine/index.html in a supported web browser.
To uninstall the VM, simply remove the folder v-machine from your hard drive.
The VM 5.0 XSLT stylesheet does support browser display. Although initial testing of the VM 5.0 showed that the XML files displayed correctly in Firefox and Chrome, you may want to transform the XML to HTML manually using an XSLT processor. You can perform this transformation in oXygen by applying the transformation scenario. Once the browser window opens with the HTML displayed in versions, save the file as a .html document.
The VM Interface
The interface for VM 5.0 is designed to be as intuitive as possible. However, there are a few new features that bear mentioning. Encoded textual notes (see Encoding Notes) appear in-line by default, where they can be viewed by hovering the mouse pointer over the letters indicating the notes’ locations. These in-line notes can be toggled off by opening the Notes Panel, which moves notes into a separate window and removes the links from within the witnesses. This can make for a cleaner viewing experience.
New in version 5.0 is the ability to change the size and location of panels, allowing you to rearrange the workspace to your liking. The workspace is always at least as large as the browser window. However, as additional witnesses are opened, the size of the workspace dynamically increases to accommodate the possibility of displaying all witnesses side-by-side. The total horizontal scrollable space is therefore determined by the total number of witnesses that are opened. The total vertical scrollable space is determined by the length of the longest open witness.
Encoding: The Basics
The following sections outline many of the fundamental elements of TEI encoding employed within the VM.
Displaying Header Information
The VM supports the display of many TEI header tags. Header information is displayed in the Bibliographic Information pop-up window in the VM, with information from headers for individual files listed sequentially and separated by horizontal rules in the order encoded.
From the <fileDesc>, the following tags are supported in the display:
- within <titleStmt>
- <title>
- <author>
- <editor>
- <sponsor>
- <funder>
- <respStmt>
- within <publicationStmt>
- <publisher>
- <address>
- <date>
- <availability>
- <notesStmt>
- <sourceDesc>
From the <encodingDesc>, the following are supported in the display:
- <projectDesc>
- <editorialDecl>
Note that since the VM will display all of the header information for every witness in the Bibliographic Information pop-up, you will want to customize information in the <listWit> as much as possible so that users can distinguish between the various versions.
For example, rather than titling the three versions of Emily Dickinson’s poem “There Are Two Ripenings,” we included within the <listWit> information that pertains to each source in order to distinguish them. Thus, one version is entitled “A 456: A poem sent to unknown recipient,” another is “A Tr60a: A poem sent by Mabel Loomis Todd to Kate Anthon,” and still another “H 47: Fascicle 14.” When the user scrolls through the information regarding each witness, it is clear which information pertains to each version.
Encoding the Body
As mentioned previously, to use the VM one must use the Critical Apparatus tagset (Chapter 12), specifically the encoding method associated with Parallel Segmentation (section 12.2.3). For detailed instructions in the TEI Guidelines see TEI P5 Guidelines and Index of Tutorials for more information on basic and advanced TEI encoding.
Included in the VM download is a set of documents for styling (vmachine.xsl, vmachine.js, vmachine.css). To edit these default styles, see the CUSTOMIZING THE VM section.
Using Transcription Tags
Because VM 5.0 is designed to aid editors creating editions with multiple witnesses, the VM supports special styling of certain TEI core tags that are used frequently when dealing with manuscript and typescript drafts, <add> and <del>. Each <add> will display in green, courier-font typeface; each <del> will display in red typeface with a strikethrough.
In addition, VM supports special styling on transcriptional choices represented by the <choice> element. The intricacies of these elements are described in section 11.3.1 in the TEI Guidelines. In brief, these elements display in the VM by displaying the original word underlined with a dashed line. Mousing over this line shows users a second word that is available for this point in the text. The second word appears in a floating box.
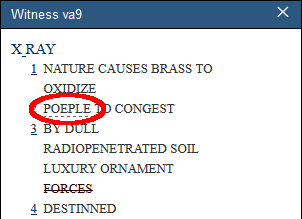
In the following example from “Xray” by Elsa von Freytag-Loringhoven, she incorrectly spells the word “People” as “Poeple.” This misspelling is encoded in <choice> to show the alternate spelling as follows.
The following is how the above encoding displays in the VM:
 |
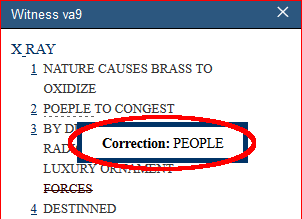 |
There are three transcriptional “choices” that are available for display in the VM:
- “Alternate spelling” using <sic> and <corr>
- “Regularized form” using <orig> and <reg>
- “Expanded abbreviation” using <abbr> and <expan>
Additionally, the VM supports <space/> (one of the elements of the TEI.transcr, the tagset for transcription of primary sources). By default only horizontal spacing is supported, and nonbreaking spaces will be added to the transcription. To use <space/> set a the @unit attribute on the on the element to char, and then a number in the @quantity attribute that represents the desired number of nonbreaking spaces.
Another supported tag is <unclear/>, an element used to express uncertainty about a word or section in the text due to illegibility of the source (see the TEI guidelines). A text encoded with <unclear/> will by default be displayed in grey.
Encoding Notes
The VM displays information in <note> in Bibliographic Information (if the tag occurs in the <teiHeader>) or as user-manipulated pop-up notes, marked by icons within the text itself. The default display for the <note> within the <text> is a small superscript N; however, if you wish to customize the icon display, you may draw from a short list of VM note types. By using the <note> attribute @type, you can alter the icon display to indicate what type of note is presented.
- b A <note type=”biographical”> pertains to biographical information.
- p A <note type=”physical”> pertains to notes regarding the physical object of the page itself.
- g A <note type=”gloss”> pertains to a gloss or definition of a word or phrase.
- c A <note type=”critical”> or <note type=”contextual”> pertains to references to critical, contextual, or secondary material information.
- n All other notes, with or without a @type attribute.
The same support of note typology is available to notes in the header. Notes from the header will display on the Bibliographic Information pop-up, preceded by the appropriate label (e.g., biographical, gloss, etc.).
Please note the <note type=”image”> in your document is reserved for image data only and will not be displayed (see section on Encoding Images) and notes in <note type=”critIntro”> will display on the Critical Introduction pop-up. To create this pop-up, simply include a <note type=”critIntro”> inside <notesStmt> within the <fileDesc> element in the <teiHeader>.
If you would prefer that either the Bibliographic Information pop-up or the Critical Introduction pop-up windows do not appear when the browser first opens, you can change this setting in the vmachine.xsl file by changing the value on the following codes from “true” to “false”:
<xsl:variable name=”displayCritInfo”>true</xsl:variable>
Encoding Images
The representation of images is optional. If you wish to display image facsimiles with your texts, however, the VM enables that functionality.
The VM image viewer will support the following image types: jpeg, gif, and png. Images larger than 600 pixels high and 600 pixels wide will be scaled to that size for display purposes.
If you are using the vmachine.xsl styling, your images should be encoded within <graphic>. The value of @url contains the path to the image while the @xml:id value is a unique id for the image. The <graphic> element is placed within <facsimile>, which is placed after the closing </teiHeader> element and before the opening <text> element.
There is a second option available for encoding references to images to be used by the VM. References to images can be tagged within a <note> with attribute @type with the value of image (i.e., <note type=”image”>). The best place to encode this is in the header’s <notesStmt>; if you wish to encode this somewhere other than the <notesStmt>, you will still need to follow the instructions below in regard to the contents of <note type=”image”>.
If your document does not already contain a <notesStmt>, you will need to enter one within your document’s <fileDesc> (typically, after the <publicationStmt> and before the <sourceDesc>) as below:
Within the @url attribute of <graphic> add a path to the first image which will take the form of “images/NAME.jpg”.The image path can also be changed using the XSLT variable in the settings.xsl file in the src folder, by setting the variable at <xsl:variable name=”facsImageFolder”></xsl:variable>
Encoding Audio
A new feature of VM5 is the support of audio and text alignment. This new feature allows for sections of a transcription of an audio recording to be linked to the corresponding sections of the audio track. Like image encoding, audio encoding is optional and can be made available for one or several transcriptions.
The VM audio player supports the .mp3 and .ogg format, and we suggest that files in both formats be available and encoded in order to ensure the best cross-browser support.
The audio tracks need to be encoded within the TEI <front> as a list of <witDetail>. The <witDetail> tag needs two attributes, @wit and @target. Both should contain a reference to a witness recorded in <listWit> (as described in the section Recording a List of Witnesses). Within the <witDetail> element, references to the audio files are encoded using <media>. On the <media> tag, the @mimeType attribute must contain the information about the type and subtype of the encoded media, and must also match the available audio files (either “audio/mp3” or “audio/ogg”). Additionally, the attribute @url is required, and its value should be the file path of the relevant audio file(s).
Individual sections of a transcription can be aligned with the audio recording using <timeline>. As suggested by the TEI guidelines (16.5.2 Placing Synchronous Events in Time), the <timeline> element is used to provide a temporal alignment of the audio and the text.
The first <timeline> element in the sequence must include an @xml:id attribute containing a unique identifier, an @origin attribute with a reference to the first <when> child element, and a @unit attribute. The value of @unit should be the character ‘s’, meaning ‘seconds’. All following <timeline> tags of the same sequence/audio track contain only a @unit attribute with the value ‘s’ (see example below).
The first <timeline> element contains two <when> element children. All following <timeline> elements contain only one <when> element each. The <when> tag indicates points in time, and all <when> elements need an @xml:id with a unique identifier, a @since attribute with a reference to a previous point in time (except for the first <when> element), and an @interval attribute indicating the amount of time in seconds. A transcription of the section of the audio recording can than be encoded in the same <app> element.
This transcription should match the section of the audio as specified with the <when> element and its @interval and @since attributes.
Encoding: Using Critical Apparatus
The Text Encoding Initiative (TEI) makes available a set of tags referred to as the “critical apparatus tagset” (TEI.textcrit) designed to provide editors with a structured method of recording differences or variations between multiple witnesses of the same text. Using this tagset allows an editor to encode multiple versions of a text in a single document. VM 5.0 is able to reconstruct multiple witnesses from the single XML-encoded document and display them, side-by-side, as individual documents. The critical apparatus tagset supports three different types of encoding variation: location-referenced, double-end-point, and parallel-segmentation; however, only parallel-segmentation and internal location-referenced encoding are supported in VM 5.0.
The advantages of using these encoding methodologies are twofold. First, it eliminates time-consuming repetition in data entry; and second, it allows for support of all of the VM’s features. The disadvantage of using these methods is the difficulty of the powerful, but rather unwieldy, critical apparatus tagging. Because of the complex nature of this type of tagging, step-by-step basic instructions on its use are provided here to supplement the TEI’s documentation.
If you are already familiar with using parallel segmentation and location-referenced encoding, you may not need to read all of this section, but skimming it may be helpful as it contains important information about how the VM interacts with certain strategies of tagging. Note also sections on Recording Variant Encoding Methodology (<variantEncoding/>) and Recording a List of Witnesses (<listWit>), as these two tags are required by the VM. Read also the section on Encoding Images if you wish to utilize the VM’s image functionality, and the section on Encoding Audio for audio functionality.
Recording Variant Encoding Methodology
The VM requires that the choice to encode by parallel segmentation or location-referenced encoding be recorded in the document header (<teiHeader>). Within the header’s <encodingDesc>, enter the <variantEncoding/> tag. It is an empty tag and thus does not wrap around any textual content (or PCDATA); instead, information pertaining to methodology is entered into attributes. The tag possesses two required attributes, @method and @location, and each is restricted to certain prescribed values. Choose parallel-segmentation or location-referenced for @method, and internal for @location. Your statement of variant encoding methodology should look like one of the following:
method=”parallel-segmentation” location=”internal”/>
method=”location-referenced” location=”internal”/>
Recording a List of Witnesses
The VM utilizes <listWit> tagging to produce multiple versions, so your document must contain a <listWit>; TEI recommends that this be added to the front matter. If you do not already have front matter in your document, enter a <front> within <text> and before <body>. Within <front>, enter a <listWit>. This is where you will record bibliographic or descriptive information pertaining to each witness and assign each witness a unique identifier. VM uses this information to reconstruct the multiple versions, and it will display the descriptions on the Bibliographic Info page so that users will be able to identify individual witnesses.
The <listWit> holds this information within
individual <witness>es. The @xml:id attribute contains the unique identifier assigned to each version. For instance, to encode four different versions of the Thomas MacGreevy poem “Nocturne,” one might construct the <listWit> as follows:
The @xml:id attribute on each <witness> assigns an abbreviation unique to that witness. You may devise your own system of naming witnesses (as is the case in the example above), or you may wish to borrow from some recognized catalogue or authority if one exists. When recording variations within the text, the value entered in the @xml:id attribute will identify the text from which each variation derives; this value will appear at the top of the panel in which that version is displayed.
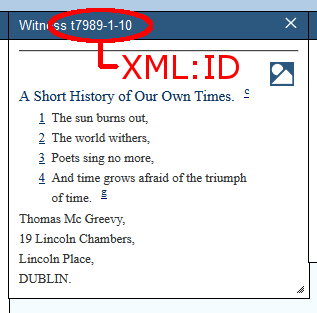
Between each set of <witness> tags, a prose statement
identifies the version by whatever bibliographic or descriptive data is appropriate; this prose statement will display in the Bibliographic Info window alongside its unique identifier so that users can ascertain the identity of each version, as illustrated below.

The @xml:id value may contain any alphanumeric string. The prose description for each <witness> may be as long or as short as you like.
The ordering of the individual <witness>es within the <listWit> corresponds to the ordering of versions in the VM display.
Using Parallel-Segmentation
Parallel-segmentation embeds variants inline and does not privilege one witness over another structurally; the other two methods require a base text with variants from other versions attached via various linking mechanisms. A basic introduction to encoding with TEI’s parallel segmentation for use in the VM follows; users are advised to consult Chapter 12: Critical Apparatus of the TEI guidelines for more information about critical apparatus tagging.
The Fundamentals of Parallel Segmentation
(Note: The instructions below are drawn from samples available on the VM site and in the downloadable ZIP file.)
The TEI critical apparatus tagging utilizes the apparatus tag (<app>), within which multiple readings (<rdg>) can be encoded. Entering an <app> into the text signifies that multiple variations are present and will be encoded at that point; each individual variant constitutes a unique <rdg>.
In parallel segmentation, variants are recorded inline. The VM supports two different methods of encoding: a “scalar” model of repetition or a procedure that embeds the variant at the exact point of variation. If, for instance, a line in one version of a poem (let’s call it witness “A”) reads “I saw a dog today” and in another version (witness “B”) reads “I saw a rhinoceros today”, you may encode it either of these two ways:
Both methods clearly show which variant belongs to which witness. In the first method, the line is repeated intact for each version. In the second method, the line tag (<l>) directly holds only those parts of the line that are common to both variants; the critical apparatus tagging is inserted only where the actual variation occurs. The VM is able to reconstruct versions from either method. The latter method, however, is recommended, particularly in prose, for two reasons: first, it avoids needless repetition; and second, it tags the exact point of variation, so readers do not have to locate for themselves the variant part of the line. That said, if the encoding is particularly complicated, you may wish to use the first method.
Note, however, that text can be highlighted by direct clicking only if it is enclosed in an <app> tag. Textual lines can always be highlighted by clicking on the line numbers, but sections of text cannot be clicked on without <app&rt; tags in place.
If, instead, you would like the user to be able to highlight each individual segment of text, you would encode the text as follows:
Let’s look at an example from a sample poem. In this Thomas MacGreevy poem, “Nocturne,” the third line varies in two versions by one word. Here is line 3 from versions t7989-1-7 and the published version (“pub”):

The two versions differ in that version a3 begins “Far above,” while the version pub begins “Far away.”
To encode this variation using parallel segmentation, the <app> is inserted after the space following the word “Far.” Two <rdg>s are enclosed within the <app>, one for each version: one <rdg> will contain the word “above” and the other the word “away.” Immediately after the second </rdg>, close the apparatus tag (i.e., </app>). In order to denote which witness contains which variant, you will need to use the attribute @wit on <rdg>. The @wit value of each <rdg> will correspond to its @xml:id value entered into the <listWit>‘s <witness> with the hashtag (#) preceding it. For instance, the <rdg> containing the word “above” has an attribute @wit value of #a3, and the <rdg> containing the word “away” has an attribute @wit value of #pub. The result will look like this:
Note that the @wit attribute is required by the VM, which will not display a reading that does not have a @wit value.
You may encode several variants within a line, and you may group together within the @wit attribute versions that agree. For instance, the same line in another manuscript version of the poem (version “a1”) looks like this:

While this line agrees with the published version in the choice of the word “away,” it departs from both versions in two places: (1) its use of the phrase “on through” for “in”; and (2) its end punctuation. Taking into account this version, our variant encoding now looks like this:
Just as in the previous example, variants are tagged with <app> and <rdg> at the point of variation and identified through the <rdg> @wit attribute. However, when considering three witnesses, two witnesses may agree but diverge from the third. While it is valid to enter three <rdg>s for each <app>, it is not necessary. To avoid repetition of the same information, you may enter two values within the @wit attribute to denote that those two witnesses agree.
The <app> tags may nest hierarchically, with a <rdg> containing an <app>, which in turn contains more <rdg>s. As this nesting can get quite complicated in practice, let’s look at a simple example first, before turning back to the MacGreevy poem. Let’s imagine that we are looking at a line from three different versions: witness A reads “I saw a dog today,” witness B reads “I saw a rhinoceros today,” and witness C reads “I heard birds singing.” We can encode this with nested apparatus like so:
</rdg>
Except for the initial word of the line, witnesses A and B disagree with witness C entirely. So following “I,” which they all share in common, an apparatus is inserted to distinguish witnesses A and B from witness C. Witnesses A and B, however, contain one variant word (“dog” or “rhinoceros”); thus, within the first level of apparatus, there is a second level inserted (after “saw a,” which they have in common, and before “today,” which they share) to encode this variant.
Back to MacGreevy. In line 3 of yet another manuscript version of the MacGreevy poem, there is more variation still:

Tagging it would render the following:
If we incorporate this fourth version into our variant encoding, we will have to embed one apparatus within another. Since only this version contains the <del> and <add> tags, it must be separated from the other three versions. In the highest level of apparatus, the first <rdg> contains version “t7989-1-2,” and the second contains the other three; within the second <rdg>, however, there is further variation in the word following “Far,” and another <app> entry is required. It might look something like this:
As you can see, the tagging can get quite complex. But because the <add> and <del> tags are present in just one witness, we need to separate this witness from the rest; by doing so, we can take advantage of VM’s rendering of the <add> and <del> tags.
Let’s consider another Macgreevy poem, “Autumn, 1922.” There are four drafts and a published version, most of which have different titles. The title of version t7989-1-10 is “A Short History of Our Own Times”; the second (t7989-1-8) has the title “CIVIL WAR” crossed out with “Ireland, Autumn 1922” written in to take its place; the third (t-7979-1-7) and fourth (t7989-1-9) bear the title “IRELAND, AUTUMN, 1922”; and the published version (pub) is entitled “AUTUMN, 1922” but the word “IRELAND” is written in before it.
The encoding of the title might look something like this:
This is simple enough, as it uses principles explored in the previous poem as well. However, “Autumn, 1922” presents at least three challenges not present in our earlier example: (1) one witness contains a third line that is omitted in the other witnesses; (2) one witness comprises one stanza, while the others comprise two; and (3) one witness splits into two lines what appears as one line in the other witnesses.
To address the first two items, let’s first compare versions t7989-1-10 and t7989-1-8:


Line three of version t7989-1-10 is missing in version t7989-1-8. The VM will support two different ways of encoding this missing line. The first inserts a line with an apparatus with only one reading:
The second method inserts two readings, one that has no content:
wit=”#t7989-1-8″></rdg>
There is a further complication here, however; two stanzas make up version t7989-1-8, while version t7989-1-10 contains only one. TEI’s critical apparatus tagging has well-known difficulties in dealing with encoding variants at a larger scale than the unit of the line; to get around this challenge in the case of a stanza break, the VM has built in the ability to read the <milestone/> tag with its @unit attribute value equal to stanza. We insert the <milestone/> tag at the point of the stanza break in version t7989-1-8 like so:
The third challenge concerns version t7989-1-7, which contains a line broken into two that other versions represent as a single line:

The VM can handle this variation in one of three ways. First, we might utilize a strategy similar to the <milestone/> method above by inserting a line break (<lb/>) at the appropriate point in version t7989-1-7:
The second method is to tag version t7989-1-7’s “Of the triumph of time” as a line which has no corresponding lines in the other two versions:
The third method is described below in “Using Location-Referenced Encoding”.
The Notion of a Base Text
Parallel segmentation does not require a base text, and structurally it does not privilege one witness over another; it does, however, allow for a base text. Should you wish to denote that one text be considered the base text from which other versions vary, you would encode those variations contained in the base text as the lemma (<lem>) instead of as a reading <rdg>. Moreover, you might use the <lem> to single out one version from the rest, whether or not it should be considered a base text. Note, however, that VM 5.0 will not display the <lem> any differently from the <rdg> without modifying the XSLT.
If, for instance, in the MacGreevy example above, you wanted version “t7989-1-3” to be considered the base text, you would encode it as follows:
wit=”#nocturne_poems”>away</rdg>
Using Location-Referenced Encoding
Location-referenced encoding is primarily useful when witnesses change across different lines in the text. If, for example, in version #t7989-1-10, the first line reads “I saw a dog”, and this line appears in version three in the tenth line, location-referenced encoding allows you to note the similarity between these two blocks of text, and the VM will display this relationship. Using location-referenced encoding is a matter of using the same value for the @loc attribute within each <app> that contains corresponding text. In the following example, from “Xray” by Freytag-Loringhoven, text within the different <app loc=”a7a”> blocks and text within <app loc=”a9b”> will display as parallel text in the VM even though they do not appear in the same line.

Line Numbering
The VM has the ability to display line numbers encoded into the TEI document. When available, they are activated by default. They can be toggled on and off by clicking on the “Line Numbers” button in the VM interface.
To make use of the line numbering feature, you would encode the text as in the following example:
withers,<milestone unit=”stanza”/></rdg>
Witness Detail
The <witDetail> records notes pertaining only to a specific witness (or witnesses); it contains the functionality of the <note> but is customized to treat witnesses. Like a <note>, a <witDetail> can occur almost anywhere within the document header or text. Because <witDetail> requires a @target attribute for linking, it is typically used to refer to one particular <rdg> and is preceded by a hashtag (#).
The <witDetail> contains two required attributes, @wit and @target. just as in the text encoding examples above, the @wit attribute records the @xml:id value (or values) corresponding to the appropriate witness (or witnesses). Thus, to return to our MacGreevy example, a <witDetail> with a @wit value of “#pub” would contain information pertaining only to the published version of the poem, but not to the manuscript versions. Likewise, a <witDetail> with a @wit value of “#t7989-1-10 #pub” would contain information pertaining to one of the manuscripts and the published version, but not to the other two manuscripts.
VIEWING WITH MANUAL FILE TRANSFORMATIONS
Because native browser XSLT support is so rare in modern browsers, you should manually transform your XML files to HTML. We recommend using the “Apply Transformation Scenario” option in oXygen for the easiest results. In oXygen,
- Open your XML file in the editing window.
- From the menu bar, select Document>Transformation>Apply Transformation Scenario.
- Your HTML document will open in your browser window. Save this document as a Web Archive in the folder entitled samples.
- Open the HTML file in your browser.
TECHNICAL INFORMATION
Files and Directory Structure
VM 5.0 resides in a folder entitled v-machine. The root directory of the folder contains several HTML files: index.html, a brief introduction to the Versioning Machine; terms.html, containing the GNU General Public Licensed under which the VM is made available; documentation.html, containing the documentation for the VM (which you are currently reading); and samples.html, a table of contents listing the sample files provided with the VM. In addition, the root directory also houses these five folders:
- The src folder contains the following:
- The javascript and xslt files that run the product (vmachine.js, vmachine.xsl, and vmachine.css). The vmachine.xsl file drives the VM for parallel segmentation and discrete witness files, respectively, by transforming the XML and calling the requisite JavaScript contained in vmachine.js.
- vmachine.css, the cascading stylesheet file that defines features of display.
- settings.xsl, which has been included to facilitate customisation of the Versioning Machine. This is explained in more detail below.
- The schema folder contains both an ODD file and an RELAX-NG schema file.
- The vm-images folder contains images associated with the VM’s user interface display.
- The images folder contains images associated with the site surrounding the VM. Please note that most image files are not included in the VM5.0 download package for intellectual property reasons.
- The includes folder contains the cascading stylesheet for the site surrounding the VM.
- The samples folder contains sample encoded files that are included for demonstration purposes. The samples folder also contains an images subdirectory that holds JPEGs of some of the sample encoded files.
Customising the VM
High-level customisation of the VM can now be accomplished through editing of the settings.xsl file in the src folder. This file is intended to allow users to change elements such as the .css file being used by the VM and the logos and icons displayed. This is useful if for branding a particular instance of the VM with your own logo. Editing this file also allows you to change the appearance of the VM when it opens, such as which panels are initially displayed. Finally, the settings.xsl file can be used to point the VM to customized .css or .js files. Detailed information about the settings.xsl file is included in the internal comments in the file itself.
Colours of the main or pop-up note backgrounds, text, or links, as well as the styling of <add>, <del>, and other elements used for transcription of primary sources, are handled with a cascading stylesheet located within the src directory: vmachine.css. You may edit it if you wish to alter any of the default choices or add special rendering to particular tags. Elements used in transcription are tagged post-transformation with a font tag that assigns an appropriate class attribute (e.g., <span class=”sic”>); you may alter the stylesheet to specify special rendering of the various classes.
If you want to use your own schema, you should place it in the src folder. While the VM does not require a unique schema, it will not work unless your documents are (1) well-formed and (2) conform to TEI’s parallel segmentation tagging as laid out above. Since the XSL file is based in the tags and hierarchies of a TEI-conformant schema with critical apparatus tagset, the VM will not work with other kinds of schemas. Thus, if you wish to use your own schema, we strongly recommend that it be a TEI-conformant schema that incorporates the critical apparatus tagset.
You may wish to preserve the look of the VM, or create your own design. If you wish to create your own, simply revise the index.html file within the samples folder to your liking. If you wish to preserve the look of the VM, however, simply replace the links to our sample files in the samples.html file with links to your own files, which should be placed within the samples folder; in this case, you may wish to also remove the link to the “Documentation” icon. To do this, simply erase this link from the index.html page: <span><a
href=”../documentation.html”>Documentation</a></span>.